编写 Prometheus Exporter: 以阿里云 Exporter 为例
去年底我写了一个阿里云云监控的 Prometheus Exporter, 后续迭代的过程中有一些经验总结, 这篇文章就将它们串联起来做一个汇总, 讲讲为什么要写 Exporter 以及怎么写一个好用的 Exporter?
何为 Prometheus Exporter?
Prometheus 监控基于一个很简单的模型: 主动抓取目标的指标接口(HTTP 协议)获取监控指标, 再存储到本地或远端的时序数据库. Prometheus 对于指标接口有一套固定的格式要求, 格式大致如下:
# HELP http_requests_total The total number of HTTP requests.# TYPE http_requests_total counterhttp_requests_total{method="post",code="200"} 1027http_requests_total{method="post",code="400"} 3
对于自己写的代码, 我们当然可以使用 Prometheus 的 SDK 暴露出上述格式的指标. 但对于大量现有服务, 系统甚至硬件, 它们并不会暴露 Prometheus 格式的指标. 比如说:
- Linux 的很多指标信息以文件形式记录在
/proc/下的各个目录中, 如/proc/meminfo里记录内存信息,/proc/stat里记录 CPU 信息; - Redis 的监控信息需要通过
INFO命令获取; - 路由器等硬件的监控信息需要通过 `SNMP** 协议获取;
- …
要监控这些目标, 我们有两个办法, 一是改动目标系统的代码, 让它主动暴露 Prometheus 格式的指标, 当然, 对于上述几个场景这种办法完全是不现实的. 这时候就只能采用第二种办法:
- 编写一个代理服务, 将其它监控信息转化为 Prometheus 格式的指标
这个代理服务的基本运作方式, 可以用下面这张图来表示:
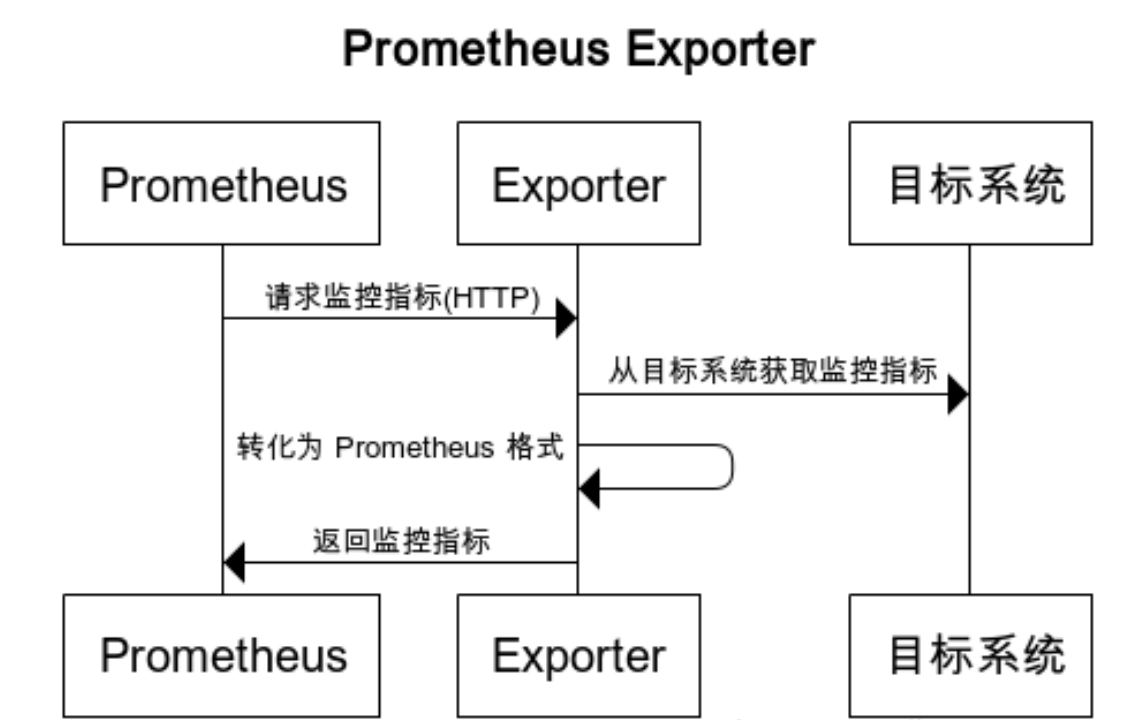
而这样的代理服务, 就称作 Prometheus Exporter, 对于上面那些常见的情形, 社区早就写好了成熟的 Exporter, 它们就是 node_exporter, redis_exporter 和 snmp_exporter.
为什么要写 Exporter?
嗯, 写 exporter 可以把监控信息接进 Prometheus, 那为什么非要接进 Prometheus 呢?
我们不妨以阿里云云监控为例, 看看接进 Prometheus 的好处都有啥:
阿里云免费提供了一部分云监控服务, 但云监控的免费功能其实很有限, 没办法支持这些痛点场景:
- Adhoc TopN 查询: 比如”找到当前对公网带宽消耗最大的 10 台服务器”;
- 容量规划: 比如”分析过去一个月某类型服务的资源用量”;
- 高级报警: 比如”对比过去一周的指标值, 根据标准差进行报警”;
- 整合业务监控: 业务的监控信息存在于另一套监控系统中, 两套系统的看板, 警报都很难联动;
幸好, 云监控提供了获取监控信息的 API, 那么我们很自然地就能想到: 只要写一个阿里云云监控的 Exporter, 不就能将阿里云的监控信息整合到 Prometheus 体系当中了吗?
当然, Exporter 就是做这个的!
集成到 Prometheus 监控之后, 借助 PromQL 强大的表达能力和 Alertmanager, Grafana 的强大生态, 我们不仅能实现所有监控信息的整合打通, 还能获得更丰富的报警选择和更强的看板能力. 下面就是一个对 RDS 进行 TopN 查询的例子:
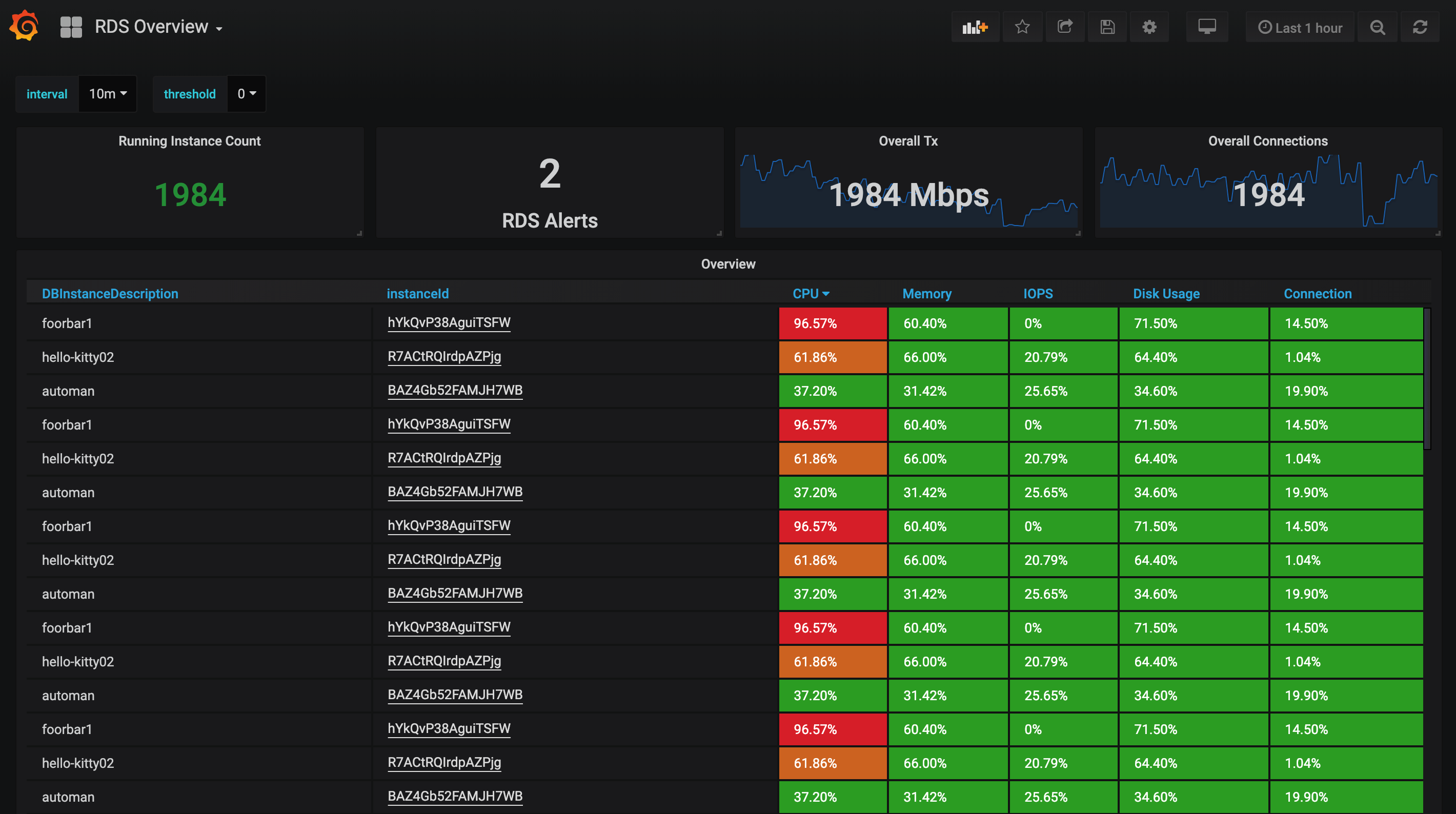
这个动机对于其它类型的 Exporter 也都是适用的: 当一个系统本身暴露了监控信息, 却又无法接入 Prometheus, 我们就可以考虑写一个 exporter 把它接进来了.
写一个好用的 Exporter
类似 “阿里云 Exporter” 这种形式的 Exporter 是非常好写的, 逻辑就是一句话:
- 写一个 Web 服务, 每当 Prometheus 请求我们这个服务问我们要指标的时候, 我们就请求云监控的 API 获得监控信息, 再转化为 Prometheus 的格式返回出去;
但这样写完之后仅仅是”能用”, 要做到”好用”, 还有诸多考量.
从文档开始
Prometheus 官方文档中 Writing Exporter 这篇写得非常全面, 假如你要写 exporter 推荐先通读一遍, 限于篇幅, 这里只概括一下:
- 做到开箱即用(默认配置就可以直接开始用)
- 推荐使用 YAML 作为配置格式
- 指标使用下划线命名
- 为指标提供 HELP String (指标上的
# HELP注释, 事实上这点大部分 exporter 都没做好) - 为 Exporter 本身的运行状态提供指标
- 可以提供一个落地页
下面几节中, 也会有和官方文档重复的部分, 但会略去理论性的部分(官方文档已经说的很好了), 着重讲实践例子.
可配置化
官方文档里讲了 Exporter 需要开箱即用, 但其实这只是基本需求, 在开箱即用的基础上, 一个良好的 Exporter 需要做到高度可配置化. 这是因为大部分 Exporter 暴露的指标中, 真正会用到的大概只有 20%, 冗余的 80% 指标不仅会消耗不必要的资源还会拖累整体的性能. 对于一般的 Exporter 而言, BP 是默认只提供必要的指标, 并且提供 extra 和 filter 配置, 允许用户配置额外的指标抓取和禁用一部分的默认指标. 而对于阿里云 Exporter 而言, 由于阿里云有数十种类型的资源(RDS, ECS, SLB…), 因此我们无法推测用户到底希望抓哪些监控信息, 因此只能全部交给用户配置. 当然, 项目还是提供了包含 SLB, RDS, ECS 和 Redis 的默认配置文件, 尽力做到开箱即用.
Info 指标
针对指标标签(Label), 我们考虑两点: “唯一性” 和 “可读性”:
“唯一性”: 对于指标, 我们应当只提供有”唯一性” 的(Label), 比如说我们暴露出 “ECS 的内存使用” 这个指标. 这时, “ECS ID” 这个标签就可以唯一区分所有的指标. 这时我们假如再加入 “IP”, “操作系统”, “名字” 这样的标签并不会增加额外的区分度, 反而会在某些状况下造成一些问题. 比方说某台 ECS 的名字变了, 那么在 Prometheus 内部就会重新记录一个时间序列, 造成额外的开销和部分 PromQL 计算的问题, 比如下面的示意图:
xxxxxxxxxx序列A {id="foo", name="旧名字"} ..................序列B {id="foo", name="新名字"} .................
“可读性”: 上面的论断有一个例外, 那就是当标签涉及”可读性”时, 即使它不贡献额外的区分度, 也可以加上. 比如 “IP” 这样的标签, 假如我们只知道 ECS ID 而不知道 IP, 那么根本对不上号, 排查问题也会异常麻烦.
可以看到, 唯一性和可读性之间其实有一些权衡, 那么有没有更好的办法呢?
答案就是 Info 指标(Info Metric). 单独暴露一个指标, 用 label 来记录实例的”额外信息”, 比如:
xxxxxxxxxxecs_info{id="foo", name="DIO", os="linux", region="hangzhou", cpu="4", memory="16GB", ip="188.188.188.188"} 1
这类指标的值习惯上永远为 1, 它们并记录实际的监控值, 仅仅记录 ecs 的一些额外信息. 而在使用的时候, 我们就可以通过 PromQL 的 “Join”(group_left) 语法将这些信息加入到最后的查询结果中:
xxxxxxxxxx# 这条 PromQL 将 aliyun_meta_rds_info 中记录的描述和状态从添加到了 aliyun_acs_rds_dashboard_MemoryUsage 中aliyun_acs_rds_dashboard_MemoryUsage* on (instanceId) group_left(DBInstanceDescription,DBInstanceStatus)aliyun_meta_rds_info
阿里云 Exporter 就大量使用了 Info 指标这种模式来提供实例的详细信息, 最后的效果就是监控指标本身非常简单, 只需要一个 ID 标签, 而看板上的信息依然非常丰富:
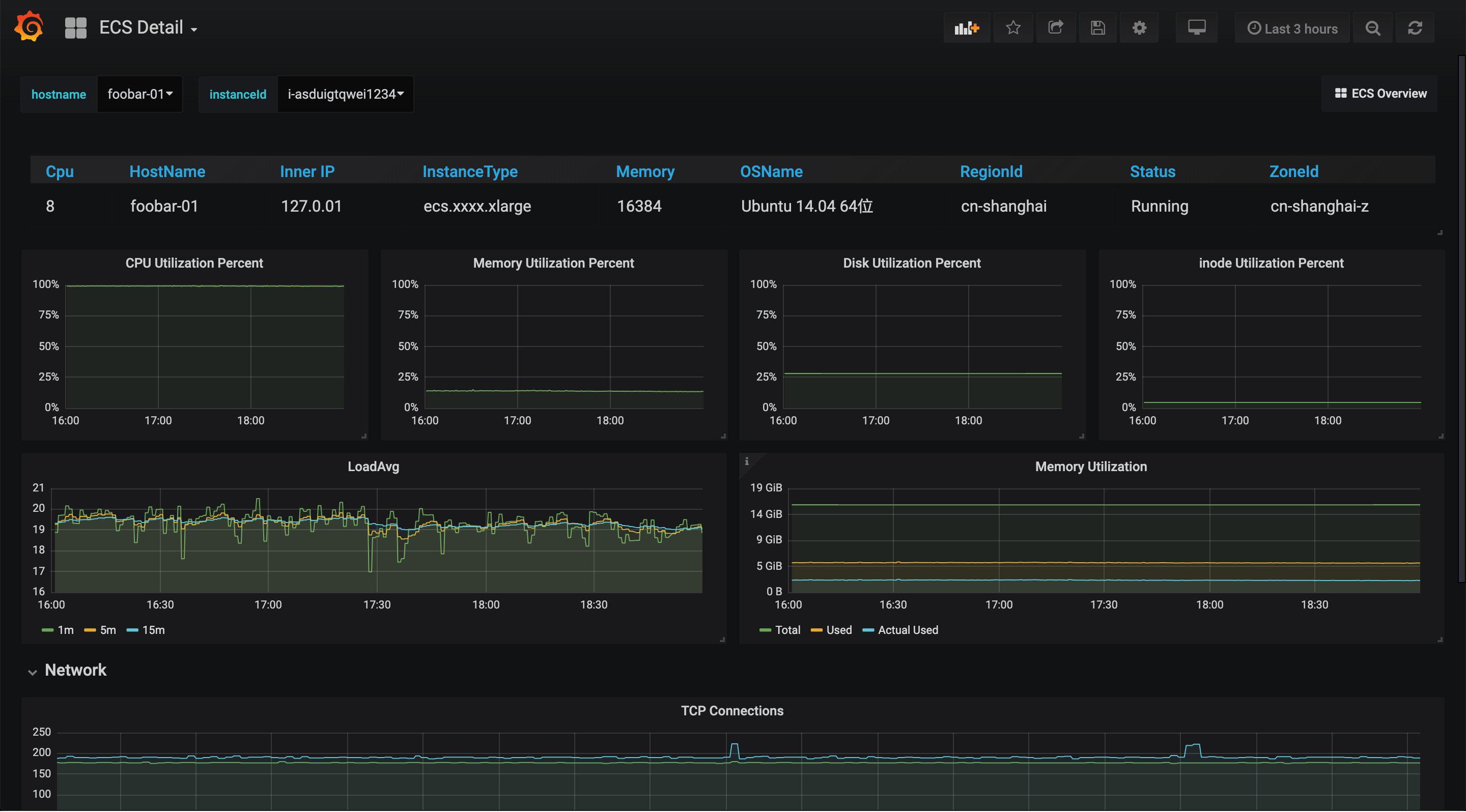
记录 Exporter 本身的信息
任何时候元监控(或者说自监控)都是首要的, 我们不可能依赖一个不被监控的系统去做监控. 因此了解怎么监控 exporter 并在编写时考虑到这点尤为重要.
首先, 所有的 Prometheus 抓取目标都有一个 up 指标用来表明这个抓取目标能否被成功抓取. 因此, 假如 exporter 挂掉或无法正常工作了, 我们是可以从相应的 up 指标立刻知道并报警的.
但 up 成立的条件仅仅是指标接口返回 200 并且内容可以被解析, 这个粒度太粗了. 假设我们用 exporter 监控了好几个不同的模块, 其中有几个模块的指标无法正常返回了, 这时候 up 就帮不上忙了.
因此一个 BP 就是针对各个子模块, 甚至于各类指标, 记录细粒度的 up 信息, 比如阿里云 exporter 就选择了为每类指标都记录 up 信息:
xaliyun_acs_rds_dashboard_MemoryUsage{id="foo"} 1233456aliyun_acs_rds_dashboard_MemoryUsage{id="bar"} 3215123aliyun_acs_rds_dashboard_MemoryUsage_up 1
当 aliyun_acs_rds_dashboard_MemoryUsage_up 这个指标出现 0 的时候, 我们就能知道 aliyun rds 内存信息的抓取不正常, 需要报警出来人工介入处理了.
另外, 阿里云的指标抓取 API 是有流控和每月配额的, 因此阿里云 exporter 里还记录了各种抓取请求的次数和响应时间的分布, 分别用于做用量的规划和基于响应时间的监控报警. 这也是”监控 exporter”本身的一个例子.
设计落地页
用过 node_exporter 的会知道, 当访问它的主页, 也就是根路径 / 时, 它会返回一个简单的页面, 这就是 exporter 的落地页(Landing Page).
落地页什么都可以放, 我认为最有价值的是放文档和帮助信息(或者放对应的链接). 而文档中最有价值的莫过于对于每个指标项的说明, 没有人理解的指标没有任何价值.
可选: 一键起监控
这一点超出了 exporter 本身的范畴, 但确确实实是 exporter “好用” 的一个极大助力. exporter 本身是无法单独使用的, 而现实情况是 Prometheus, Grafana, Alertmanager 再对接 Slack, 钉钉啥的, 这一套假如需要从头搭建, 还是有一定的门槛(用 k8s 的话至少得看一下 helm chart 吧), 甚至于有些时候想搭建监控的是全栈(gan)工程师, 作为全公司的独苗, 很可能更多的精力需要花在跟进前端的新技术上(不我没有黑前端…). 这时候, 一个一键拉起整套监控系统的命令诱惑力是非常大的.
要一键拉起整套监控栈, 首先 kubernetes 就不考虑了, 能无痛部署生产级 kubernetes 集群的大佬不会需要这样的命令. 这时候, 反倒凉透的 docker-compose 是一个很好的选择. 还是以阿里云 exporter 为例, 仓库提供的 docker-compose stack 里提供了 Prometheus, aliyun-exporter, Grafana(看板), Alertmanager(发警报), alertmanager-dingtalk-webhook(适配 alertmanager 的警报到钉钉机器人) 的一键部署并且警报规则和 Grafana 看板页一并配置完毕. 这么一来, 只要用户有一台装了 docker 的机器, 他就能在5分钟之内打开 Grafana 看到这些效果(还有钉钉警报…假如这位用户的服务器不太健康的话):
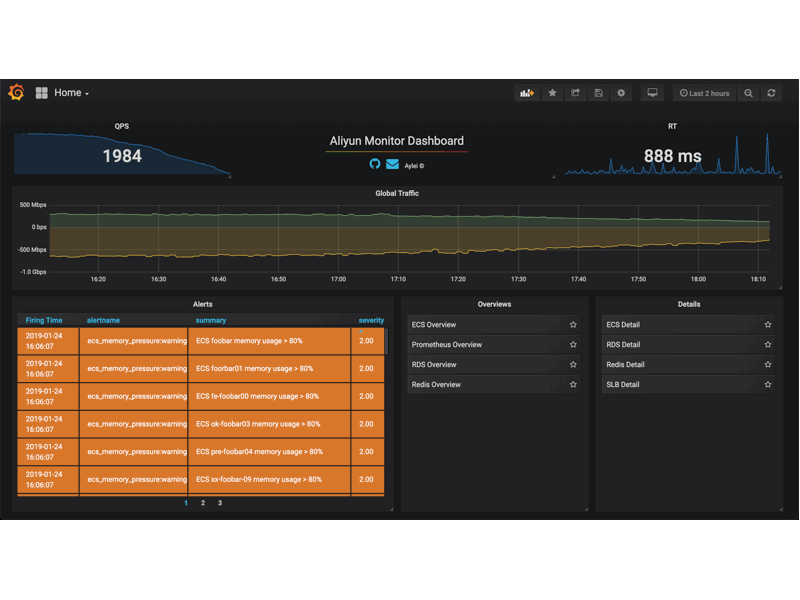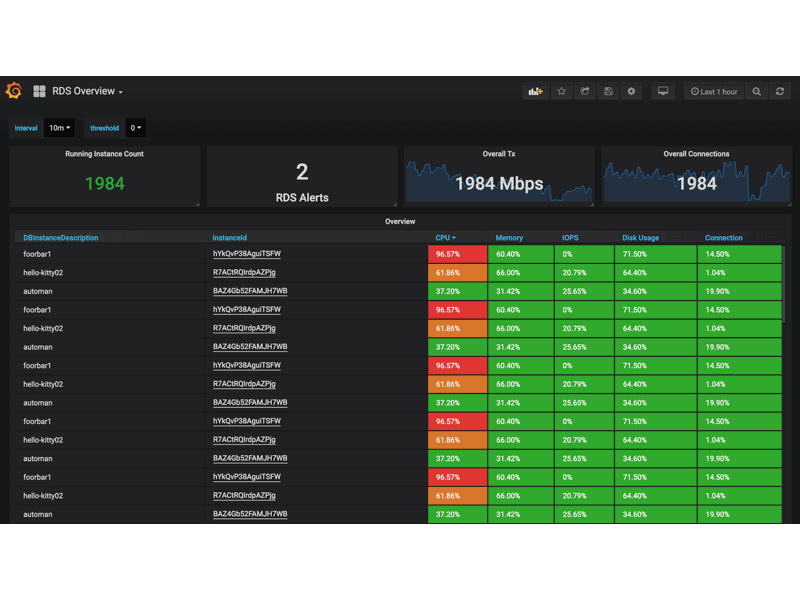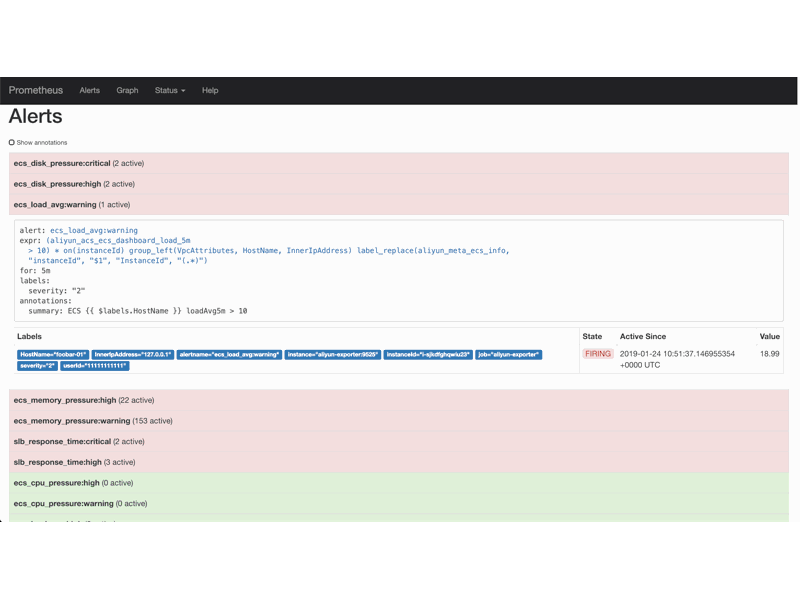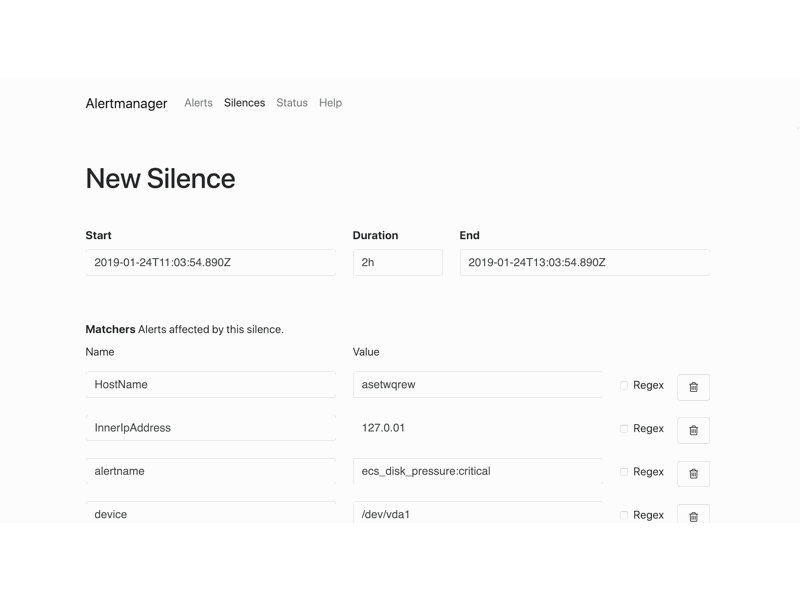
当然了, 想要稳固地部署这套架构, 还是需要多机做高可用或者直接扔到 k8s, swarm 这样的编排系统上. 但假如没有”一键部署”的存在, 很多对 Prometheus 生态不熟悉的开发者就会被拒之门外; 另外, 对于有经验的用户, “一键部署”也能帮助他们快速理解这个 exporter 的特性, 帮助他们判断是否需要启用这个组件.
结语
你可能已经看出来了, 这篇文章的本意是打广告(当然, 我已经非常努力地写了我所认为的”干货”!). aliyun-exporter 这个项目其实最开始只是我练习 Python 用的, 但在前几天碰到一位用户告诉我他们在生产中使用了这个项目, 这给了莫大的鼓舞, 正好我还没有在公开场合 Promote 过这个项目, 因此这周就捞一把, 希望项目本身或这些衍生出来的经验中有一样能帮到大家吧.
都看到这了, 不如点个 star?
3715 Words
2019-04-14 11:13
f5b842d @ 2019-05-14
快速了解prometheus如何编写exporter
发表于 2020-12-16 09:58阅读:1229评论:0推荐:0
前言
在开始监控你的服务之前,你需要通过添加prometheus客户端来添加监控。 可以找 第三方exporter 监控你的服务,也可以自己编写exporter。
目前已经有很多不同的语言编写的客户端库,包括官方提供的Go,Java,Python,Ruby。 已有客户端库
在了解编写exporter之前,可以先5分钟学会搭建prometheus
简单的exporter服务
先写一个简单的http服务,在9095端口启动了一个能够为prometheus提供监控指标的HTTP服务。你可以在 http://localhost:9095/metrics 看到这些指标。
xxxxxxxxxxpackage mainimport ("github.com/prometheus/client_golang/prometheus/promhttp""net/http")func main() {http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {w.Write([]byte("hello world"))})http.Handle("/metrics",promhttp.Handler())http.ListenAndServe(":9095",nil)}
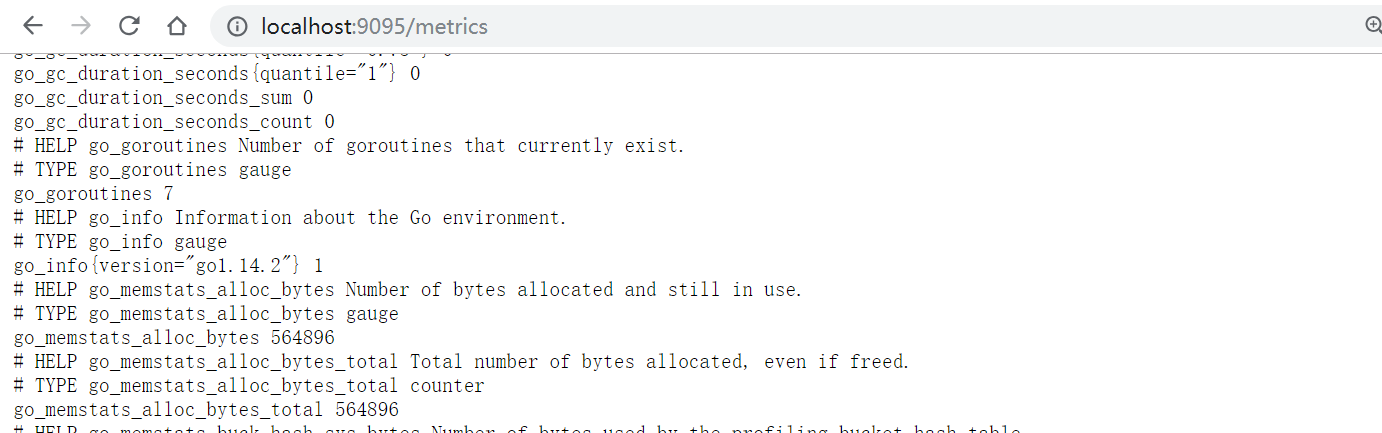
虽然偶尔会手动访问/metrics页面查看指标数据,但是将指标数据导入prometheus才方便。
xxxxxxxxxxglobal:scrape_interval: 15s # 默认抓取间隔,15s向目标抓取一次数据external_labels:monitor: 'prometheus-monitor'# 抓取对象scrape_configs:- job_name: 'exporter' # 名称,会在每一条metrics添加标签{job_name:"prometheus"}scrape_interval: 5s # 抓取时间static_configs: # 抓取对象- targets: ['localhost:9095']
那么在 http://localhost:9090/ 浏览器输入 PromQL 表达式 go_info,就会看到如图的结果
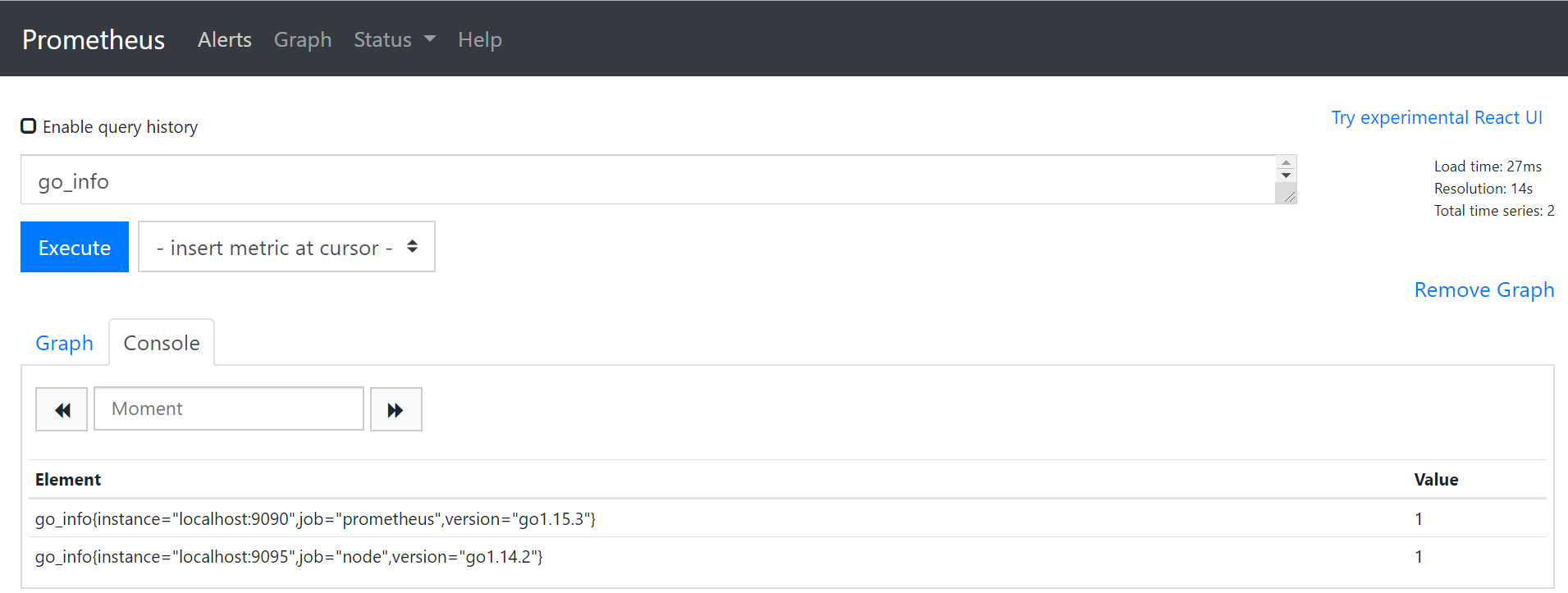
监控指标
Counter(计数器类型)
Counter记录的是事件的数量或大小,只增不减,除非发生重置。
Counter主要有两个方法
xxxxxxxxxx# 将counter加1Inc()# 增加指定值,如果<0会panicAdd(float64)
xxxxxxxxxxpackage mainimport ("github.com/prometheus/client_golang/prometheus""github.com/prometheus/client_golang/prometheus/promauto""github.com/prometheus/client_golang/prometheus/promhttp""net/http""time")var (failures = prometheus.NewCounterVec(prometheus.CounterOpts{Name: "hq_failture_total",Help: "failure counts",},[]string{"device"})// 可以使用promauto自动注册success = promauto.NewCounterVec(prometheus.CounterOpts{Name: "hq_failture_total",Help: "failure counts",},[]string{"device"}))func init() {prometheus.MustRegister(failures)}func main() {go func() {failures.WithLabelValues("/dev/sda").Add(3.2)time.Sleep(time.Second)failures.WithLabelValues("/dev/sda").Inc()time.Sleep(time.Second)failures.WithLabelValues("/dev/sdb").Inc()time.Sleep(time.Second)failures.WithLabelValues("/dev/sdb").Add(1.5)}()http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {w.Write([]byte("hello world"))})http.Handle("/metrics",promhttp.Handler())http.ListenAndServe(":9095",nil)}
Gauge(仪表盘类型)
Gauge是可增可减的指标类,更关注于数值本身。
Gauge主要有几种方法
xxxxxxxxxx# 设置任意值Set(float64)# 加1Inc()# 减1Dec()# 加任意数,如果是负数,那么就会减去Add(float64)# 和当前值的差值Sub(float64)# 设置值为当前时间戳SetToCurrentTime()
xxxxxxxxxxpackage mainimport ("github.com/prometheus/client_golang/prometheus""github.com/prometheus/client_golang/prometheus/promhttp""net/http""time")var (failures = prometheus.NewGaugeVec(prometheus.GaugeOpts{Name: "hq_failture_total",Help: "failure counts",},[]string{"device"}))func init() {prometheus.MustRegister(failures)}func main() {go func() {failures.WithLabelValues("/dev/sda").Add(5)failures.WithLabelValues("/dev/sdb").Set(10)time.Sleep(time.Second * 5)failures.WithLabelValues("/dev/sda").Inc()failures.WithLabelValues("/dev/sdb").Add(3)time.Sleep(time.Second * 5)failures.WithLabelValues("/dev/sda").Dec()failures.WithLabelValues("/dev/sdb").SetToCurrentTime()time.Sleep(time.Second* 5)failures.WithLabelValues("/dev/sda").Sub(1)failures.WithLabelValues("/dev/sdb").Dec()time.Sleep(time.Second* 5)time.Sleep(time.Second)}()http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {w.Write([]byte("hello world"))})http.Handle("/metrics",promhttp.Handler())http.ListenAndServe(":9095",nil)}
Summary(摘要类型)
表示一段时间数据采样结果,由count,sum构成
Summary只有一种方法
xxxxxxxxxxObserve(float64)
你可以访问 /metrics 可以看到hq_failture_total_sum和hq_failture_total_count

hq_failture_total_sum代表观察值的总和
hq_failture_total_count代表观察到的条数
xxxxxxxxxxpackage mainimport ("github.com/prometheus/client_golang/prometheus""github.com/prometheus/client_golang/prometheus/promhttp""net/http""time")var (failures = prometheus.NewSummaryVec(prometheus.SummaryOpts{Name: "hq_failture_total",Help: "failure counts",},[]string{"device"}))func init() {prometheus.MustRegister(failures)}func main() {var count float64go func() {t := time.NewTicker(time.Second)for {count++failures.WithLabelValues("/dev/sdc").Observe(count)<-t.C}}()http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {w.Write([]byte("hello world"))})http.Handle("/metrics",promhttp.Handler())http.ListenAndServe(":9095",nil)}
Histogram(直方图类型)
summary可以提供平均延迟数据,但是如果你想要分位数呢?
那么就可以使用Histogram分位数.
Histogram只有一种方法
xxxxxxxxxxObserve(float64)
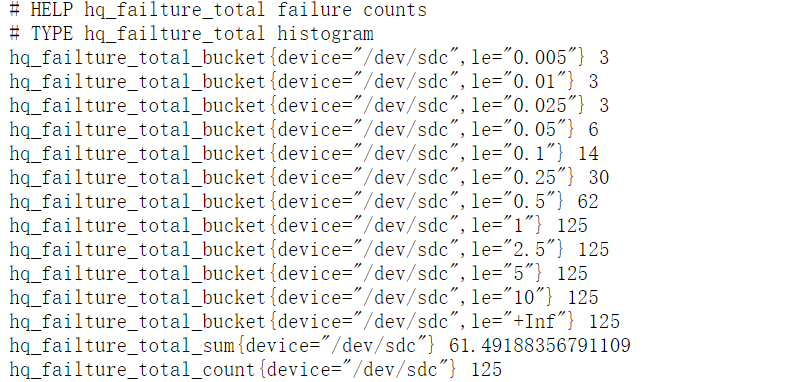
你可以访问 /metrics 可以看到hq_failture_total_sum和hq_failture_total_count、hq_failture_total_bucket
xxxxxxxxxxpackage mainimport ("github.com/prometheus/client_golang/prometheus""github.com/prometheus/client_golang/prometheus/promhttp""math/rand""net/http""time")var (failures = prometheus.NewHistogramVec(prometheus.HistogramOpts{Name: "hq_failture_total",Help: "failure counts",},[]string{"device"}))func init() {prometheus.MustRegister(failures)}func main() {go func() {t := time.NewTicker(time.Second)for {failures.WithLabelValues("/dev/sdc").Observe(rand.Float64())<-t.C}}()http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {w.Write([]byte("hello world"))})http.Handle("/metrics",promhttp.Handler())http.ListenAndServe(":9095",nil)}
那么什么是bucket(桶)?桶记录小于监控指标的数量 默认的buckets范围为{0.005,0.01,0.025,0.05,0.075,0.1,0.25,0.5,0.75,1,2.5,5,7.5,10}
PromQL函数histogram_quantile可以用来统计桶中的分位数。例如,0.95分位数的表达式为 histogram_quantile(0.95,rate(hq_failture_total_bucket[1m]))
如何给指标命名?
Prometheus 指标需要以字母开头,后面可以跟着任意数量的字母,数字,下划线。
命名的整体结构是 library_name_unit_suffix
虽然 [a-zA-Z_:][a-zA-Z0-9_:]* 是Prometheus中有效的命名规则的正则表达式,但你要避免是有某些有效值。 你不应该在测控指标使用冒号,因为它是为记录规则中使用而保留的。以下划线开头的名称是为prometheus内部使用而保留的。
total,count,sum和bucket这些后缀是留给counter,summary和histogram指标使用的。 除了在counter类型的指标上始终具有_total后缀外,不要将其他后缀放在指标名称的末尾。
yarn_exporter
mob649e8160f07c 2023-07-22 03:10:47©著作权
Yarn Exporter: 为您监控Hadoop Yarn集群的工具
引言
在大数据领域中,Hadoop Yarn是一个广泛使用的集群资源管理系统。它的主要作用是有效地管理集群资源,并为不同的应用程序提供资源分配和调度。然而,在大型集群中,监控和调试Yarn集群的性能和健康状态可能是一项挑战。为了解决这个问题,开发了一个名为yarn_exporter的工具。本文将介绍yarn_exporter的作用、工作原理以及如何使用它来监控Yarn集群。
yarn_exporter是什么?
yarn_exporter是一个用于监控Hadoop Yarn集群的开源工具。它是Prometheus生态系统的一部分,可以将Yarn集群的监控指标导出为Prometheus可识别的格式。通过使用yarn_exporter,您可以方便地收集和可视化Yarn集群的关键性能指标,以帮助您更好地了解集群的工作状态。
yarn_exporter的工作原理
yarn_exporter通过使用Yarn的REST API和JMX接口来获取Yarn集群的监控指标。它会定期从Yarn集群中获取指标数据,并将其转换为Prometheus格式。然后,yarn_exporter会暴露一个HTTP端点,以供Prometheus服务器进行拉取指标数据。
如何使用yarn_exporter
下面是一些使用yarn_exporter的步骤:
在您的Yarn集群中部署
yarn_exporter。您可以从GitHub上的yarn_exporter仓库中获取最新的发行版。编辑
yarn_exporter的配置文件yarn_exporter.yml,指定Yarn集群的相关配置信息,例如Yarn的REST API地址、端口号等。xxxxxxxxxx# yarn_exporter.ymlclustername"my_cluster"address"http://yarn-cluster:8088"启动
yarn_exporter。xxxxxxxxxx$ ./yarn_exporter --config.file=yarn_exporter.yml配置Prometheus服务器以收集
yarn_exporter的指标数据。在Prometheus的配置文件中添加以下内容:xxxxxxxxxx# prometheus.ymlscrape_configsjob_name'yarn_exporter'static_configstargets'localhost:9115'启动Prometheus服务器。
xxxxxxxxxx$ prometheus --config.file=prometheus.yml打开Prometheus的Web界面,导航到
Graph选项卡,您可以开始探索和可视化从yarn_exporter收集的Yarn集群指标数据了。
示例代码
以下是使用Python编写的一个简单的示例代码,演示如何使用yarn_exporter的API获取Yarn集群的监控指标:
xxxxxxxxxximport requests
def get_yarn_metrics(): response = requests.get('http://localhost:9115/metrics') if response.status_code == 200: return response.text else: return None
metrics = get_yarn_metrics()if metrics: print(metrics)else: print('Failed to fetch Yarn metrics')
结论
yarn_exporter是一个非常有用的工具,可以帮助您监控和调试Hadoop Yarn集群。通过将Yarn集群的监控指标导出为Prometheus格式,您可以方便地收集和可视化这些指标,以更好地了解集群的工作状态。希望本文对理解yarn_exporter及其使用方法有所帮助。
【注意:以上代码示例仅供参考,具体实现可能会根据环境和需求有所不同】